Leading 10 Scraping Tools In 2023 For Efficient Data Extraction It is a valuable strategy for companies calling for long-lasting data preservation and is specifically useful for information migrations, as it specifically exports heritage data. Information scuffing is a method made use of to get information from sites, data sources and applications. The first circumstances of Get more info web crawling returns to 1993, which was a substantial year for this innovation. In June of that year, Matthew Gray established the Net Wanderer Offsite Link to determine the size of the net. Later that year, this was made use of to create an index called the "Wandex", and this enabled the first internet online search engine to be produced. [newline] Today, we take that for given with major internet search engine supplying a riches of outcomes almost immediately. Browser expansions are smaller sized software program applications that increase the abilities of an internet internet browser, making them easy to set up and make use of. Nonetheless, they use fewer features and are limited by the capacities of the browser. However, establishing an information scraping pipe nowadays is uncomplicated, needing minimal shows effort to meet useful needs. We integrate a combination of predefined regulations, triggers, and AI to recognize violent traffic. In today's hectic, data-driven market, business must be able to swiftly and precisely extract beneficial understandings from the substantial quantities of information available online. Businesses are embracing the power of internet information extraction to acquire valuable understandings and drive growth. As organizations progressively recognize the power of data-driven decision-making, the demand for data extraction options will remain to rise.
Not Even the Ghost of Obsolescence Can Coerce Users Onto ... - Slashdot
Not Even the Ghost of Obsolescence Can Coerce Users Onto ....
Posted: Mon, 09 Oct 2023 07:00:00 GMT [source]
Is Information Scuffing Lawful?
And just how to identify the trend before any individual else does, otherwise with the aid of information? Web scratching will be the top tool utilized by equity study in the future. Looks bright as the appeal of Internet use increases, in addition to the amount of information readily available around the web Nowadays, it does not really matter in which industry you are operating as practically every person begins utilizing the internet eventually.ChatGPT Can Now Browse the Internet - Slashdot
ChatGPT Can Now Browse the Internet.
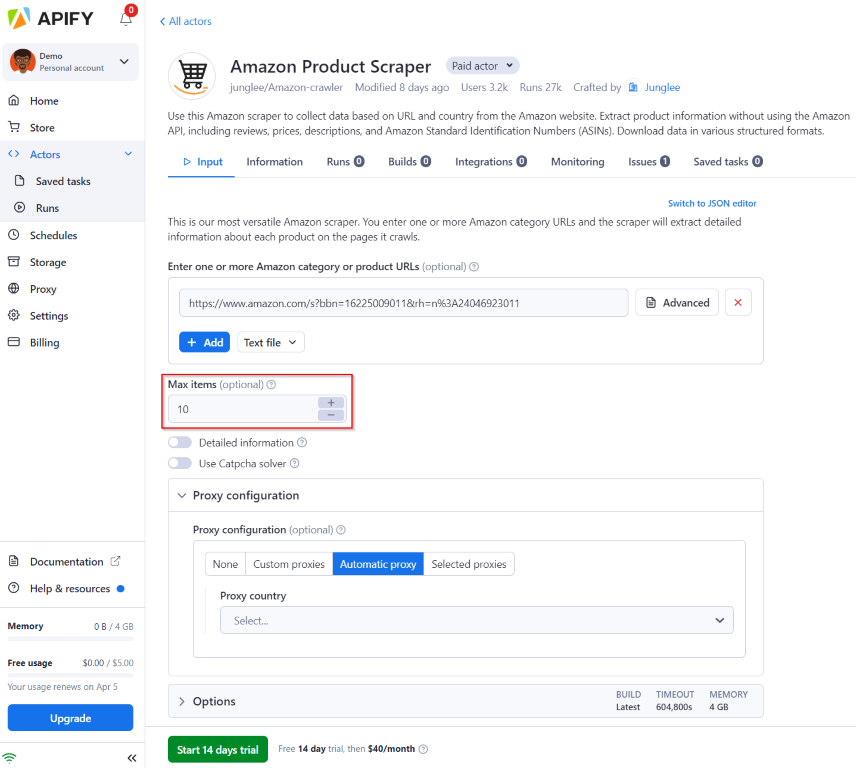
.png)
Posted: Wed, 27 Sep 2023 07:00:00 GMT [source]
Python For Data Science
This technique can avoid intensive CPU usage during company hours, can reduce end-user permit costs for ERP customers, and can provide extremely fast prototyping and advancement of custom records. Whereas data scraping and web scratching entail interacting with vibrant output, record mining involves removing information from files in a human-readable layout, such as HTML, PDF, or text. These can be conveniently generated from almost any system by obstructing the information feed to a printer. This method can supply a fast and basic path to obtaining data without the need to configure an API to the source system.- Popular Python tools, such as Scrapy, Beautiful Soup, and Selenium, are extensively utilized for data scuffing tasks.But regardless of the acknowledged value of outside data, couple of companies are in fact taking advantage of such information, claims McKinsey.Web scuffing tasks are mosting likely to expand significantly, and they're right here to stay.